All Politics Is Local; All Political Data Is National
In a divided America, what's average is rarely typical.

This article is the second in a four-part series about the Pew 2022 midterm report and common errors in conventional election analysis. Read the first article, “Confirmation Bias Is a Hell of a Drug,” here.
A foundational flaw with contemporary political analysis is the presumption that what is true generally in the United States is also true in whichever state or jurisdiction matters at the moment.
Much of what “everyone knows” about politics depends on taking for granted that what is characteristic of a group is also characteristic of the individuals in the group. Formally, these are known as ecological fallacies. Informally, many ecological fallacies – once they are sufficiently discredited – come to be known as stereotypes or prejudices.
In my previous post on confirmation bias, I called out the Procrustean style of political analysis – where, like Procrustes in the Greek myth, the “limbs” of the actual evidence on elections are either chopped off or stretched in order to fit the “bed” of conventional wisdom. In this post, we’ll see how that conventional wisdom often depends on ecological fallacies, which is why heroic Procrustean measures become necessary to maintain it.
I’ll begin with illustrations of a few of the most common ecological fallacies in circulation. Along the way, we’ll see that Pew’s “gold standard” validated voter study1 of the 2022 midterms offered easy offramps from believing some of the silliest ecological fallacies about demographics – but the media sped past those offramps, insisting on continuing to go in the wrong direction in spite of the evidence. (And they don’t even have Siri to calmly recalculate new directions for them.) From there, we’ll see how those same unexamined assumptions prevent even Pew from giving us useful data about some of the most important political questions facing us now.
Buyer Beware: An Illustrated Guide to Ecological Fallacies
Here are some examples of how ecological fallacies distort our understanding of elections.
Mean vs. Median vs. Multimodal Distributions
Assuming without evidence that the average (or mean) for a group (the sum divided by the number of group members) is typical of the members in the group is one of the most common ecological fallacies. Averages work best when the distribution is strongly “normal” – when most members are very close to the average value. This is the normal distribution that we take for granted as true anytime we accept the mean as a useful descriptor.

But not everything has a normal distribution.
Example: Let’s assume there are 10 people in a group, nine earning $50,000 a year and Jamie Dimon, who made about $35 million last year. The average income in the group is $3.45 million. It is comically wrong to expect that any member of the group would have the same lifestyle or buying habits as someone making $3.45 million annually – 9 of them won’t make that much in their entire lifetime, and the tenth probably can’t imagine the sacrifices he’d have to make to live with that paltry sum.
In that example, it would work better to look at the modal income (using the mode, or most common value), which would be $50,000 - we’d be correct 90 percent of the time. We would properly orient ourselves to thinking about someone making $50,000. Jamie’s concerns wouldn’t matter. (If only.) In this instance, the median would have worked just as well. This graph shows a typical right-skewed distribution to illustrate the terms.

The median or mode works well here, but that’s not always the case.
Example. Now, let’s assume that Jamie invites Jeff, Elon, Peter, Warren, and five of their best friends into the group, which has now grown to 19. Now, because the distribution is bimodal (two big peaks) neither the mean nor the median tells us anything useful about the group.
We are in an era of frequent bimodal distributions, but we too often still look at mean and median, even when they are meaningless. For example, partisanship is bimodal – most people are consistently on the edges (supporting one party over the other), not in the middle (equally likely to support either party). In any given state, this is what the typical distributions of partisans looks like (0 indicates a strong Republican, 100 indicates a strong Democrat):

While this chart almost certainly resonates with you because I said it describes a state, it’s actually a demographic group: Latino voters. The problem is that we can easily understand bimodal distributions in geographic areas because that kind of polarization is part of our dominant narrative, but we don’t realize that the same is true within most demographic groups as well. Explaining politics in terms of demographic groups is compelling because those groups seem to capture important divisions in our society – college vs. non-college, urban vs. rural, etc. But when we leave it there, we don’t see that most of those demographic distinctions are meaningfully fractal – that within the set of, say, college-educated voters, there are dividing lines that can create as large a gap as the one between college and non-college voters.
Or consider this – we understand that while national partisan margins are small, in most states they are fairly large – there are just a few battleground states. That’s shown in the following graph. Yet, an almost identical share of people live in closely contested precincts in the five battleground states as do in the other 45 states. (Ten percent in the former, 9 percent in the latter.) In other words, individual neighborhoods in Arizona, Georgia, Michigan, Pennsylvania, and Wisconsin are no more likely to be up for grabs than neighborhoods in deep Red or deep Blue states; the only thing that makes them swing is the near perfect parity between Democrats and Republicans in the aggregate across the state.

Further complicating matters is the fact that not everything in politics is bimodal.
Example: We wouldn’t be surprised to learn that the outcomes of congressional races don’t fit a normal distribution. We expect it to look like the last graph – U-shaped, with a lot of races easily Democratic or Republican and only a few up for grabs. But here is the actual distribution of Democratic margin for the 435 midterm races. (Remember, the “Democratic margin” is the Republican share of the vote subtracted from the Democratic share; a district with a 60-40 D-R split would have a 20-point Democratic margin.) Exactly like the bell curve at the top of this section, the X-axis is the Democratic margin and the Y-axis is the frequency (how many races ended up with that margin), with the mean being the Democratic margin nationally (-2 points adjusted for uncontested races).2

By now, it should be clear that the problem is the same as with my earlier examples about the 10 people. In this case, rather than one outlier throwing off our understanding of the whole group, we have an entire group of 435 House races that are dissimilar enough from one another that it makes no sense to consider all of them as one group. Before we start generalizing about a group, we have to make sure that the group members are sufficiently alike with respect to whatever we are interested in understanding.
To see what I mean, let’s compare two of the demographic groups that are most frequently discussed in political terms – white non-college voters and Black voters – with the purpose of understanding partisanship. Each data point on the graph below represents the Democratic margin for each combination of generation, urbanity, gender, and region. Among those combinations, Democrats do as well as +44 percent and as badly as -53 percent with white non-college voters, a range of 97 points. On the other hand, among those combinations, Democrats do as well as +84 percent and as “poorly” as +45 percent with Black voters, a range of just 40 points. With respect to partisanship, one is a cohesive group; the other is not. It’s impossible to find a subgroup of Black voters who are close to majority Republicans, but it’s easy to slice and dice “white non-college” into some Democratic and some Republican subgroups. Indeed, it should be baseline malpractice to choose demographic categories in which one substantial portion is Democratic and another substantial portion is Republican.

False Trends: Compositional Errors
The holy grail of political punditry is finding a new demographic trend in voting behavior. Nearly everything you’ve read about the partisanship of any particular demographic group, like Latinos or non-college voters, conveys the sense that the individual voters in that group are becoming more or less Democratic – in other words, that they are changing their minds en masse.
The first section looked at ecological fallacies related to descriptive statistics (like mean and median). Now, let’s assume that we have a solid descriptive category and look at the serious ecological fallacies that arise when the behavior of the group is compared between two time periods. We call these kinds of errors compositional. A compositional error occurs when we ignore how changes in who is in the group affect the averages of the group as a whole over time.
Example: Let’s assume that in our original group of 10 people – the nine $50,000-a-year earners and Jamie Dimon – one has cancer. (It’s up to you whether it’s Jamie Dimon or one of the others.) The cancer rate for the group is 10 percent. Now, let’s say that our cancer patient dies. Now the cancer rate for the group of nine is 0 percent. Yet no one in the group is any healthier than they were before. Or, let’s say that one of the healthy people left the group; the cancer rate would spike to 11 percent, but again, no one in the group is any less healthy than they were before that. Thus, for example, when a Democratic-leaning Gen Z’er decides to vote and a Republican-leaning member of the Greatest Generation does not, another demographic category the two of them share – say, non-college voters – becomes more Democratic, even though no individual non-college Republican has become more Democratic-leaning.
I only saw one piece, in the Washington Post, that tried to incorporate Pew’s findings about subgroup turnout, with really smart graphs like these that show both the level of support and turnout for each selected segment of voters.
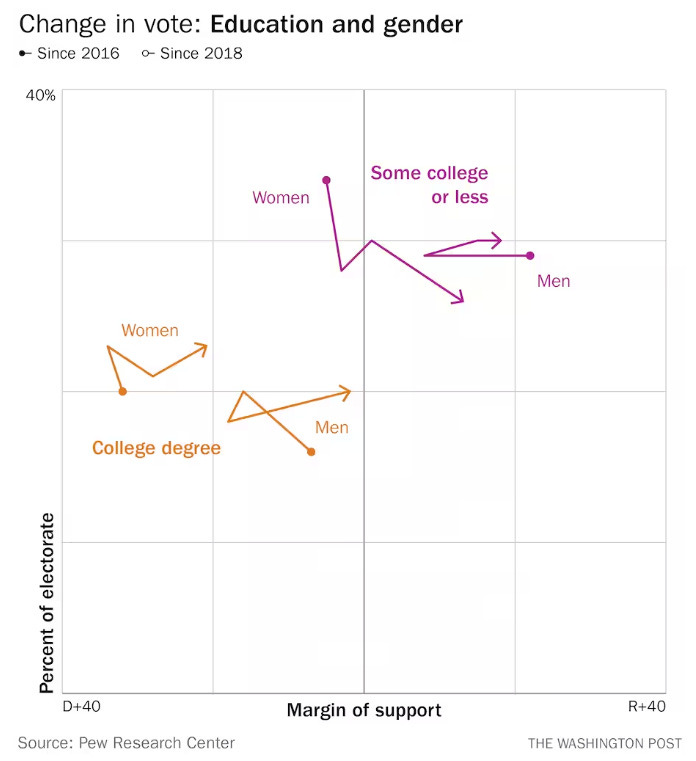
These graphs allow us to see three things we usually don’t:
Subgroups matter – a lot. Subgroups within familiar demographics – say, gender as a subgroup of educational attainment or urbanity – do not move in tandem. (Again, this shouldn’t be surprising, but believing that they do move in tandem is implicit in the decision to treat educational attainment or urbanity as sufficiently descriptive.)
Compositional Impact. If a more Democratic segment, like women college voters, increases its share of the electorate, the Democratic margin of college voters will increase, without any individual college voters actually becoming more Democratic. Yet we never hear that as a reason for changes in partisanship; we only hear about how some news event or other supposedly changed people’s minds.
Drunken sailors. We also see that in almost no case do we see straight lines from cycle to cycle to cycle. If we pay close enough to what we are told are trends, we can see as often as not, they look more like random walks.
Now, look at the change in Democratic margin from 2020 to 2022 for race/ethnicity. Overall, the Democratic margin declined by 7 points, more than any single race/ethnicity did. How is that possible? How could every segment of the population decline by less than the total population declined? Simple – disproportionate turnout by the more Republican segments of the electorate.

Really, really sit with this. In anticipation of both the 2020 and 2022 elections, the primary focus of most political analysts was how well Democrats were doing with various demographic groups. Yet even if that were perfectly known, experts would have missed the mark unless they knew the proportions of who would turn out as well.
It’s often said that all models are wrong, but some are useful. Models require two things: a logic and inputs. In order to be useful, the model’s logic needs to hold up in the real world when we know the value of the inputs that go into that model. For instance, a physicist can’t tell you how fast an object is falling unless you tell her how many seconds it’s been falling so she could plug that into the formula (32 feet per second squared). If that formula failed in real life, the physicist wouldn’t make excuses for why it didn’t work “this time,” but go back to the drawing board and develop a better model. When, for instance, the New York Times publishes a model that purports to predict the next election if we have the right inputs, we can test the efficacy of that model after we know the real-world results. In this case, that model was way off about the Senate.3
How Polling Generates Ecological Fallacies
Suppose you wanted to know what the most likely total every time you roll two dice would be. The dice had been rolled hundreds of times last year, but you ignore those results because, after all, it’s a new year. The first day you roll the dice you get a 4, the next day a 7, then an 8, and a 5, and so on. Now think of the results for a particular demographic group in each survey as being a dice roll. The first dice roll of 4 would produce breathless headlines that it’s not 7 anymore! And then there would be reports that Democrats were steadily improving with the group, but then fell back. And no doubt, whichever the direction, some contemporaneous event could plausibly be presented as the cause. (Although in practice, only trends that are consistent with expectations are reported, thus creating generalized reinforcement for the narrative.) But the underlying expected value never really changed. It was always the case that the most likely outcome for your dice roll was going to be somewhere around 7, with plenty of variation.
Why does this distorted narrative happen? Let’s call it “squeezing the balloon.” Imagine a balloon with several sets of lines drawn on it that are perfectly parallel when the balloon is deflated. When you partially inflate it and try to squeeze it such that one set of lines are parallel, you will send more air to another part of the balloon and make those other lines even less parallel than they were before.
As you likely know, the days of random sample surveys are long gone, succumbing to vanishingly low phone response rates. That means that pollsters have to develop methodologies to weight the interviews they do complete, usually to benchmarks for the demographics that they believe are most important.
Even if pollsters accurately weight their chosen demographics, doing so usually means that they will inadvertently give too much weight to subgroups of those demographics who are more likely to take surveys. For example, until 2016, few pollsters weighted white voters by education because there was not enough of a difference between how white college and white non-college voters voted. As a result of the huge miss in 2016, pollsters began to weight by white education as well. But, when they did so, white non-college voters who were more likely to take surveys (like office workers) were overweighted compared to those who were less likely to take surveys (like manual laborers).
As the central finding of the Pew report clearly states, shifts in partisanship by individual voters were so rare as to be almost inconsequential in the midterms: “Shifts in turnout, as opposed to defections, were responsible for most of the changes in vote margins from the 2018 midterms within most subgroups in the population.” (Logically, this has to be true if any voting segment’s Democratic margin changes but individuals in the segment do not switch sides.)
Thus, pretty much every story you read in 2021 or 2022 about this or that demographic group swinging one way or the other4 did not reflect people in that group changing their minds. Those stories mostly reflected that from poll to poll, either the ratio of subgroups within demographics changed (as in the Washington Post graphs above), or the ratio of Biden to Trump voters taking the poll was changing.
Pew: Can’t See the Trees for the Forest
When we look at how Democrats or Republicans did “nationwide” in any given election year, we are for the most part looking at the aggregate of the results of separate statewide or congressional elections, very few of which actually resemble the average. Likewise, when we hear that, say, Biden received 37 percent of the white non-college vote, we take for granted that this was more or less the case in every state, and – even more irrationally when said out loud – that it’s as true of Gen Z as of Boomers, or as true of Evangelicals as of atheists.
In this section, I’m going to show what happens when all you care about is the forest.
Senators Masters, Walker, Laxalt and Oz
If voters shifted away from Democrats as they had nationally in Arizona, Georgia, Nevada and Pennsylvania, Messrs. Masters, Walker, Laxalt and Oz could easily be freshmen senators now.
If what you want to understand about the 2022 midterms is how voter support nationally swung away from House Democrats5 by six points from two years before, broken down by a wide variety of demographic groups, you can’t do better than Pew’s recent midterm report. But, with that approach, Pew can tell us literally nothing about what was most historic and consequential in these midterms – a series of victories for The Emerging Anti-MAGA Majority that has transformed American politics since Trump's shocking win in 2016.
In 2022, Democrats actually improved their performance from 2020 in the 15 states where MAGA candidates were in competitive races for senator and/or governor. In those 15 states, Democrats gained 1.5 points compared to 2020. But in the other 35 states, they suffered a historically routine 6.8 point loss, which came out to a 6-point overall loss nationwide.6 The difference between the states where Democrats won and lost – as the data in Pew makes clear, and as I have written about extensively – was that in states where the MAGA threat was salient, turnout that far surpassed expectations from America’s Anti-MAGA Majority.

These kinds of state-specific trends are exactly what our nationally-oriented political commentary industry is designed to miss. Think about it – we have an entire industry and analytical framework to answer questions about the national electorate, even though there isn’t a single election in which the outcome rests on what the “national” electorate prefers. The electorates of individual states and/or congressional districts are all that matters.
Regional Differences Still Matter Most
Perhaps we still can’t get past Barack Obama telling us that there are no red states or blue states, just the United States. But, since no later than 2008, any proper understanding of federal elections has to begin by accepting that we have three political ecosystems. These ecosystems are best understood as regions of Blue, Red, and Purple states. Each state has bluer and redder regions within it, of course, but under our peculiar constitutional system, states are the sovereign units even in national elections. (For all the sniping about whether America is a democracy or a republic, the truth is that America is functionally a federal republic with democratic elections.) All three regions – Blue, Red, and Purple – have their own different dynamics born of their different histories, political traditions, civic institutions, and economic foundations. These differences are especially stark between Red and Blue, as the Purple states are definitionally less polarized.
That regional factors are the major driving force in politics is not a passing phase, but the most foundational fact in American partisan history. Going back to the Civil War, only in the period between the Depression and the end of the Cold War did voters in both Red and Blue regions provide majorities to the same candidate for president. During the Jim Crow era and since the end of the Cold War, Red and Blue states have usually gone in opposite directions by consistently large margins. The next graph has bars only for presidential elections in which each region chose a different candidate by at least 5 points. (In the pre-New Deal period, Red indicates Confederate states and Blue Union states; after that, Red and Blue comprise their current definitions.)

In “Congressional “Class Inversion” or Sectional Reversion?” I showed that the Democratic and Republican House Caucuses are divided by essentially the same regional differences, and to roughly the same extent, as they were during Jim Crow up to the Depression.
Moreover, those regional partisan differences are also reflected in all the popular demographic groups. The following graph shows what that looks like for all of the most often cited voting segments.7 As you can see, while the different groups within a demographic set remain consistent in their relative partisanship to each other, every single demographic group is meaningfully more Democratic in Blue states than Purple states, and more Democratic in Purple states than in Red states. Indeed, there isn’t a single group plotted that isn’t Democratic leaning in Blue states, and only a few that are not Republican leaning in Red states.

Conclusion
This has been a pretty math-y post, so I want to step back and make sure you don’t throw up your arms screaming “nothing works.”
There is a real tension here. On the one hand, we all want to have reliable mental frameworks that help us understand how the world works, and that give us tools to develop strategies and have expectations. You can’t do that without simplifying things and creating something like stereotypes that work. I would venture that one significant source of the problems I’ve laid out is that data science was developed to handle physical phenomena, which it handles fantastically. The problem begins when political data scientists try to use all those powerful tools that work when distributions look normal. But, politics is not a normal phenomenon in the United States. For example, as I mentioned above and have written about extensively elsewhere, America has anything but a single political ecosystem, but our data science assumes it does. We fail from the get go.
A second reason has to do with the incentive structure for the media, and for academics (to an extent). It’s really quite inexpensive to conduct a survey now, especially when, until Election Day, there is no right answer to be held accountable to. Polling creates a simulacrum in which nothing inside its four corners can be “wrong” as long as it has internal consistency. But we need a political science that strives for external validity. That’s messy and more expensive. It would mean counting and curating all sorts of other kinds of data and using that to triangulate to conclusions we could be more confident in. The irony is that we spend enough on polling now to get much better answers, but as long as the incentives are quick hits for the news media (another headline! More clickbait!) and academia (another published paper!), what we get is much, much less than the sum of our spending. To be concrete - the media could pool a fraction of what it spends on polling now to gain joint access to a high quality voter file.
There are other reasons as well, but I’ll have more to say about those in future posts.
The Pew validated voter studies of the last four elections provide one of the the most rigorous and comprehensive views of the electorate, combining high-quality polling, panels which can isolate whether individual voters are changing their allegiances, validation on the voter file, and inclusion of eligible voters who did not cast ballots.
Here, and throughout, I am using adjusted House vote. Adjusted House vote incorporates the routine adjustment made by election statisticians to adjust the national raw vote totals for the differential between uncontested races with Democratic and Republican candidates. For example, in 2018, Democrats won the raw vote by 8.6 points, but are considered to have won by only 7.3 or 7.4 points after accounting for how many more Democrats ran unopposed. The reverse is true in 2022, where Democrats' likely loss in the raw vote will be 2.8 points, but 1.9 or 2.0 points after adjusting for more Republicans running unopposed.
Since we now know that Democrats lost nationally by about 2 points (an option worse than the lowest offered in the interactive), we can give the simulator a whirl. The graphic shows Republicans flipping Arizona and Georgia, and retaining Pennsylvania. If we also posit that education polarization is getting worse (as many pundits argue is happening), the result is “Democrats lose the Senate. Democrats will most likely capture 47 seats, with a 10% chance they’ll control the Senate.” In this scenario, Republicans flip Nevada, but keep Arizona.
Hereinafter, just “Democrats,” as that is what the Pew data addresses.
To get an idea of how unusual that is, in 2022, House Democrats did better than they had in 13 states two years earlier. In the previous 4 midterms beginning in 2006, the president’s party did better in only 4, 3, 8, and 5 states.
Not shown are Black voters as their much higher margin throws the visual scale off. In addition, compared to other selected segments, there is less variation between the regions for Black voters.
Thanks for this. The anti-maga majority is growing, especially through young voters. I’m working to have a voter registration drive in every HS with TheCivicsCenter.Org