

Why Polling Is Opinion Journalism, In One Chart
We need to talk about the “margin of pollster.”

In our poll-saturated political coverage, we are treated almost daily to dramatic graphs like the one below. Indeed, the Substack Opinion Today scours the coverage and delivers a dozen or more links to stories based on survey results every day.
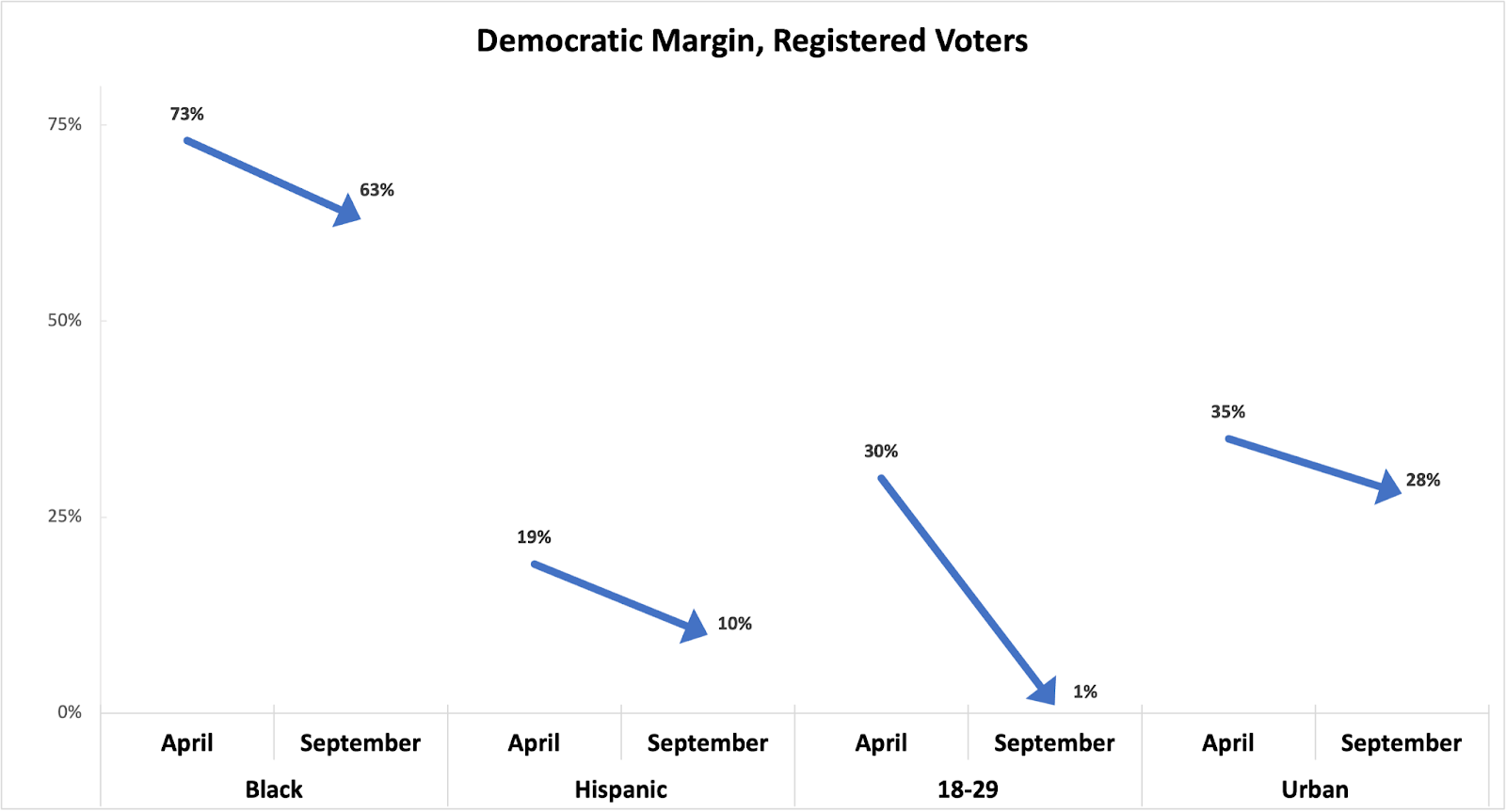
Especially if the data was collected by the highest quality public pollsters like the Pew Research Center or the New York Times, a graph like the one above instantly triggers days, if not weeks or months, of stories about a major realignment in American politics, with a long line of commentators competing to offer the best explanation for the phenomenon – or the ultimate brass ring, naming rights to it.
Imagine if, as indicated in the same polls, key trends this year included:
The diploma divide exploded from 26 points in April to 35 points in September. And among white voters it jumped from 37 to 49 points!
The vast generational divide nearly vanished, shrinking from 35 points to just 4 points!1
The gender gap exploded, nearly tripling from 12 points to 30 points!
The ensuing conventional wisdom would quickly conclude that although on balance the shift from Biden to Harris improved Democrats’ prospects overall, the swap from Scranton Joe to San Francisco Harris predictably cost working class white voters. But, on the other hand, women are all in for Kamala.
There’s only one problem with the graph above. The data points are real, but the dates are not. “April” is actually the results of a Pew survey of registered voters, and “September” is a New York Times survey of registered voters – both fielded over almost exactly the same time period.2 I could have reversed the order to show an illusory bounce for Harris in the opposite direction on all counts.
Here’s the real data:
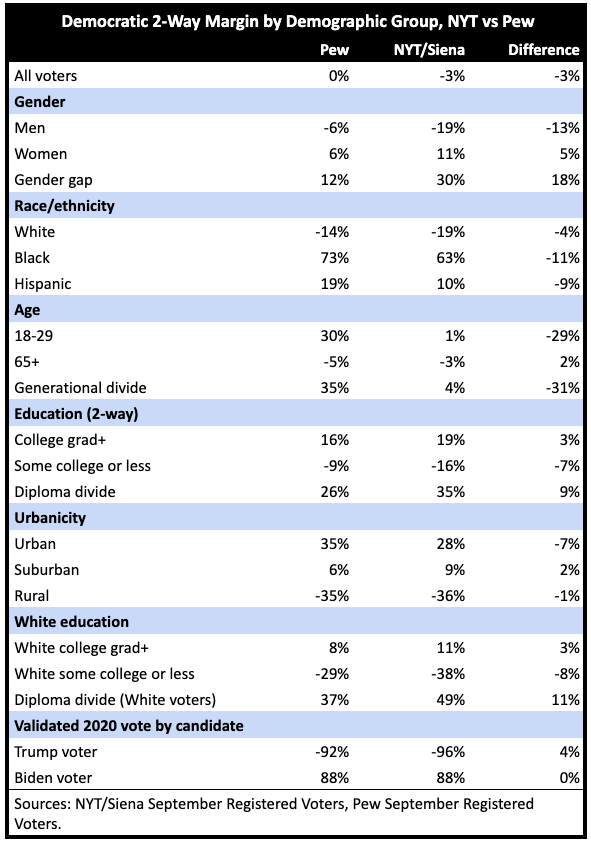
Overall, Pew found the race to be dead even, while NYT/Siena found Trump ahead by 3 points.3
A 3-point difference in the national margin doesn’t sound like a big deal; it’s probably within the margin of error. But when you get into the crosstabs of specific demographic groups, the results are all over the map.
Beware the Margin of Pollster
To be clear, I am not trying to “unskew” or impugn the integrity of Pew or NYT/Siena. I am also not using the Pew survey to say the more pessimistic NYT/Siena survey is wrong, or any such thing.
We very often see very wide variations between subpopulations in different surveys that have exactly the same result for the horse race. This reflects what I call “squeezing the balloon” – the downstream consequences of the pollsters’ decisions about how to weight what is inevitably an unrepresentative sample. I explained this in some technical depth last year in “Terrible Food, and Such Small Portions,” one of four in-depth posts about the Pew validated voter study and broader issues about political data journalism.
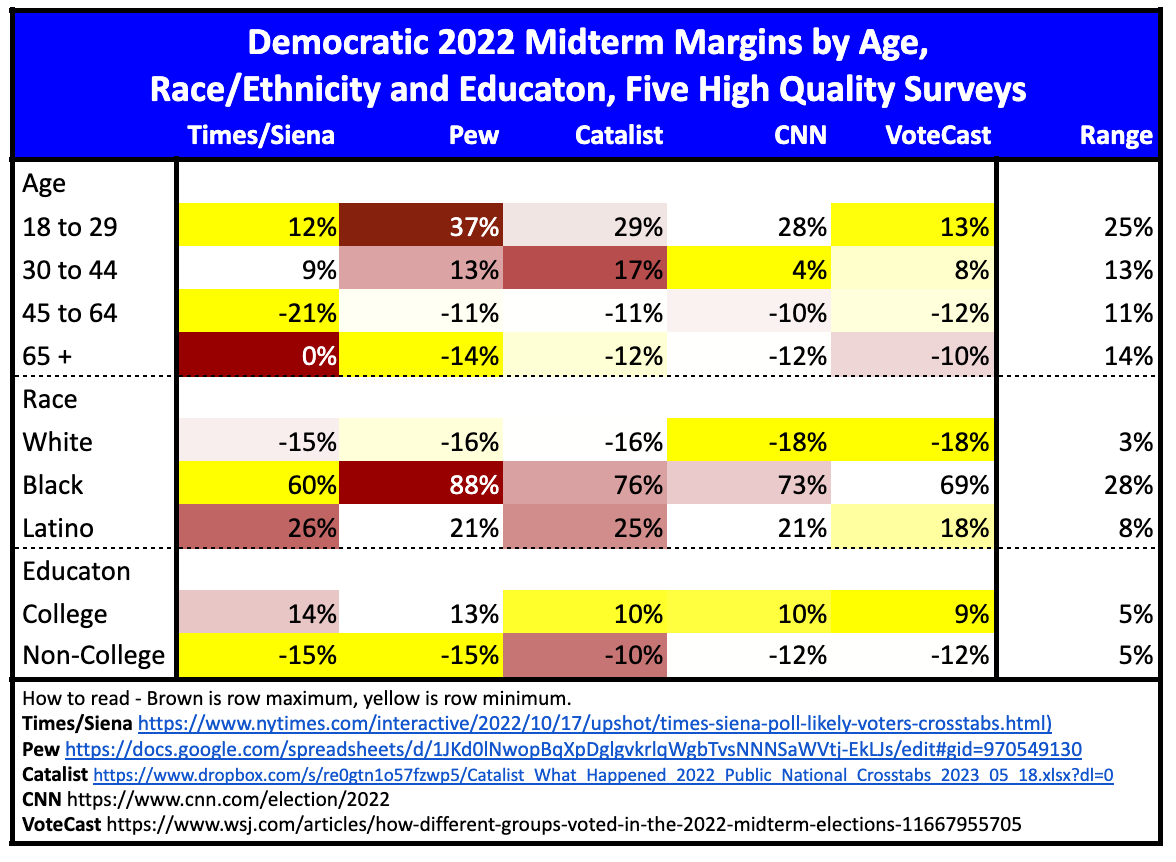
For instance, this chart shows the very large variation in subgroup margins even for the final results of the 2022 midterms, among five very high-quality surveys. (I compared post-election data from Pew, Catalist, CNN, and VoteCast, as well as the final pre-election New York Times/Siena survey.)
We can call this the MOP – margin of pollster. Nate Cohn ingeniously called attention to the MOP in September 2016, when he shared his survey dataset with four highly respected pollsters and came up with this:

You’ll notice that I just shifted from talking about subgroups to talking about overall horse race margins. While the differences are more dramatic at the subgroup level, the same principle and problem applies to every horse race poll result.
This is why I call polling and forecasting opinion journalism. The “opinions” are not about issues or ideology, but about methodological approaches. Unfortunately, something about the way we humans are wired makes most of us much more credulous when it comes to experts who speak in numbers than experts who rely solely on words. And our insatiable desire for certainty on the question of “who will win?” creates an irresistible temptation for corporate media to monetize our very justified anxiety.
My broader point is that, as Nate Cohn noted last month, “No one ever knows which polls — or which polling methodologies — will appear ‘right’ or ‘wrong’ until the election results begin to arrive.”
But even then, we won’t know whether either Pew or NYT/Siena was correct this week. And I would argue there isn’t even a “right” answer now, in the sense that those in the commenting class who rip-and-read from these polls mean it.
There’s a darker side to the proliferation of polls – they have created an all you can eat buffet of “hard evidence” for commentators to support their preferred position in debates over party policies and strategy. Indeed, we no longer have robust debates over policy – instead, those differences are argued in terms of whether a preferred policy will help Democrats win.
Finally, the most fundamental question is whether the future our children and grandchildren inherit from us is better served by our having the best possible ephemeral estimate of how many people support Harris or Trump today, or by our having the best possible public understanding of the full extent to which the freedoms we value are on the line.
For more in-depth conversations about the limitations of polling, see my recent appearances on the CrossTabs podcast: “Vaccines for Mad Poll Disease” and “The Two Americas.”
Weekend Reading is edited by Emily Crockett, with research assistance by Andrea Evans and Thomas Mande.
18-29 year olds versus those 65 or older.
Pew - August 26th to September 2nd; NYT/Siena - September 3rd to 6th.
In case there is confusion about the NYT headline Trump 2 point lead: the New York Times releases results for all registered voters as well as for likely voters. The more widely reported 2-point margin in NYT/Siena was of likely voters, and that was the universe I used in my last post, About that Times Poll. But here, since the point is to compare their results to the Pew survey, which only reports results for registered voters, I use the NYT/Siena registered voter result which was 3 points. That said, more confusion creeps in because the NYT/Siena result is a a “rounded” 3 points since the reported topline is 48-46.
This newsletter is a revelation. Thank you for doing it. I wish the people that drool over every new poll had this context at the ready. Thanks again!
Thanks for the data interpretation.
Mark Twain: “There are lies, damned lies, and statistics.”